线段树简介
线段树常用来解决多次区间修改以及区间性质查询的问题, 且区间的性质一般可以由子区间推出, 如最大值、区间和。
线段树的结构
线段树顾名思义显然是一棵树, 且一般实现为二叉树。 线段树满足:
树上每一个结点都代表着一段区间
每个结点的两个子结点分别代表该区间的左右子区间。
如区间[1, 5]用线段树表示为
graph TD;
A(("[1, 5]")) --> B(("[1, 3]"))
A --> C(("[4, 5]"))
B --> D(("[1, 2]"))
B --> E(("[3, 3]"))
C --> F(("[4, 4]"))
C --> G(("[5, 5]"))
D --> H(("[1, 1]"))
D --> I(("[2, 2]"))
显然, 线段树具有搜索树的性质。
基本建树
线段树的存储
线段树常用存储完全二叉树的方式、数组形式存储, 即根结点下标为1,
对于结点i, 它的左儿子下标为2 * i,
右儿子下标为2 * i + 1。
下面以图的形式展示各结点下标关系
graph TD;
A(("1
[1, 5]")) --> B(("2
[1, 3]"))
A --> C(("3
[4, 5]"))
B --> D(("4
[1, 2]"))
B --> E(("5
[3, 3]"))
C --> F(("6
[4, 4]"))
C --> G(("7
[5, 5]"))
D --> H(("8
[1, 1]"))
D --> I(("9
[2, 2]"))
至于数组的大小, 一般开到区间长度的四倍, 因为结点个数最多不会操过区间长度的四倍, 可自行证明。
代码实现
假设区间性质为区间和
1 | const int N = xxx; |
线段树的单点修改及查询
例题 - 洛谷P3374
题目描述
如题,已知一个数列,你需要进行下面两种操作:
- 将某一个数加上 x*
- 求出某区间每一个数的和
输入格式
第一行包含两个正整数 n,m*,分别表示该数列数字的个数和操作的总个数。
第二行包含 n 个用空格分隔的整数,其中第 i 个数字表示数列第 ii 项的初始值。
接下来 m 行每行包含 33 个整数,表示一个操作,具体如下:
1 x k含义:将第 xx 个数加上 k2 x y含义:输出区间 [x,y][x,y] 内每个数的和输出格式
输出包含若干行整数,即为所有操作 2 的结果。
输入输出样例
输入 #1
2
3
4
5
6
7
>1 5 4 2 3
>1 1 3
>2 2 5
>1 3 -1
>1 4 2
>2 1 4输出 #1
2
>16说明/提示
【数据范围】
单点修改
在区间和线段树已经构建完成的情况下, 此时若要将某元素的值增大,则会有多个区间的和发生变化。
因此可以对线段树进行一次搜索, 将所有包含被修改元素的区间的区间和增大。
1 | //k, l, r表示当前区间的下标及边界, x、y为被修改的元素下标和增大的值 |
显然单点修改线段树的时间复杂度与树高有关, 为
区间查询
由于区间和是可以由子区间推出的, 所以要求出[b, e]区间的区间和, 就要把[b, e]区间分解为若干个线段树上存在的区间。
如
graph TD;
A(("[1, 5]")) --> B(("[1, 3]"))
A --> C(("[4, 5]"))
B --> D(("[1, 2]"))
B --> E(("[3, 3]"))
C --> F(("[4, 4]"))
C --> G(("[5, 5]"))
D --> H(("[1, 1]"))
D --> I(("[2, 2]"))
若要查询[3, 5], 则应该分解为[3, 3] + [4, 5]
1 | int query (int k, int l, int r, int b, int e) { |
查询时, 最坏情况下最遍历到最底层, 且支数是有限的, 时间复杂度为
完整代码
1 | // |
线段树的区间修改及查询
例题
【模板】线段树 1
题目描述
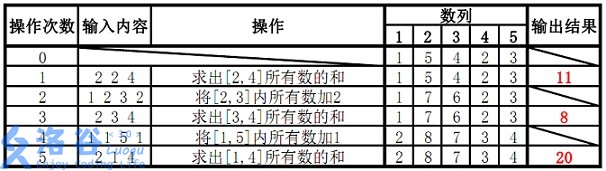
如题,已知一个数列,你需要进行下面两种操作:
- 将某区间每一个数加上
。 - 求出某区间每一个数的和。
输入格式
第一行包含两个整数
,分别表示该数列数字的个数和操作的总个数。 第二行包含
个用空格分隔的整数,其中第 个数字表示数列第 项的初始值。 接下来
行每行包含 或 个整数,表示一个操作,具体如下:
1 x y k:将区间内每个数加上 。 2 x y:输出区间内每个数的和。 输出格式
输出包含若干行整数,即为所有操作 2 的结果。
样例 #1
样例输入 #1
2
3
4
5
6
7
1 5 4 2 3
2 2 4
1 2 3 2
2 3 4
1 1 5 1
2 1 4样例输出 #1
2
3
8
20提示
对于
的数据: , 。
对于的数据: , 。
对于的数据: 。 保证任意时刻数列中所有元素的绝对值之和
。 【样例解释】
区间修改与永久懒惰标记
这次要求将区间所有元素都加上某个数, 直接遍历加上再重新建树肯定不行,
这样时间复杂度会来到
这时我们需要用一个懒惰标记的手段, 对于修改的区间[b, e], 我们把它分解为线段树上若干的区间, 对这些区间增加一个“标记”, 即标记增加了x。而对分解区间的父区间, 则是直接修改f值。
如下图, 假设为在[3, 5]区间加上x, 且用v[N<<2]来记录某结点区间加的值。
graph TD;
A("1
[1, 5]
f[1] += (5-3+1) * x") --> B("2
[1, 3]
f[2] += (3-3+1)*x")
A --> C("3
[4, 5]
v[3] += x")
B --> D(("4
[1, 2]"))
B --> E(("5
[3, 3]
v[5] += x"))
C --> F(("6
[4, 4]"))
C --> G(("7
[5, 5]"))
D --> H(("8
[1, 1]"))
D --> I(("9
[2, 2]"))
1 | void modify (int k, int l, int r, int b, int e, int x) { |
区间查询
v[i] += x表示在对i号结点区间[l, r]上的每个元素都加上了x, 所有包含[l, r]的大区间也都已经都记录了变化; 但如果我们要查询的是[l, r]的子区间呢?
这时对懒惰标记的处理就至关重要了, 在向下遍历线段树的途中用一个变量来记录沿途的标记, 最后在加到被查询区间上。
如
graph TD;
A("1
[1, 5]
v[1] = x") --> B(("2
[1, 3]
"))
A --> C("3
[4, 5]
v[3] = y")
B --> D(("4
[1, 2]"))
B --> E(("5
[3, 3]
"))
C --> F(("6
[4, 4]"))
C --> G(("7
[5, 5]"))
D --> H(("8
[1, 1]"))
D --> I(("9
[2, 2]"))
此时v[1]和v[3]上均有标记, 若我们要查询[4, 4]的区间和,
在搜索改区间的过程上会记录路径上的所有标记的和,
所以结果应该为f[6] + (x + y) * (4 - 4 + 1)
1 |
|
完整代码
1 |
|
标记下传与自下而上更新
在上述标记永久化方法中, 对标记的处理方法是:
- modify时的被标记区间的父区间不标记, 而是直接修改。
- query时, 会累加遍历路径中的标记, 最后作用于查询区间。
但使用标记永久化的很重要的一个条件是标记可以累加, 很多时候可以并不能满足。
而标记下传是适用性更广的一种标记处理方法, 有两个核心方法:
- pushdown, 把当前结点的标记下传
- pushup, 由子结点更新当前结点。
标记下传的基本规则是:
- 为某结点添加标记时, 会修改结点的值。
- 在遍历到线段树的某个结点时, 若还要往下遍历, 则把标记下传, 并在遍历完子树后更新当前结点。
标记下传是一种延迟修改的思想, 在修改[l,
r]时如果直接把它的每一个子区间都修改, 显然在时间复杂度上是灾难。
但标记下传只在需要查询/修改子区间时把上一次的修改作用于子区间,
修改的过程融合在了查询/其它修改 的过程中。 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
using namespace std;
using ll = long long;
const int N = 1e5 + 10;
ll a[N], f[N << 2], v[N << 2];
void pushup(int k) {
f[k] = f[2 * k] + f[2 * k + 1];
}
void pushdown(int k, int l, int r) {
if (v[k]) {
int left = 2 * k, right = left + 1, m = (l + r) >> 1;
f[left] += v[k] * (m - l + 1), f[right] += v[k] * (r - m);
v[left] += v[k], v[right] += v[k], v[k] = 0;
}
}
void build(int k, int l, int r) {
if(l == r) {
f[k] = a[l];
return;
}
int m = (l + r) >> 1;
build(2 * k, l, m), build(2 * k + 1, m + 1, r);
pushup(k);
}
void modify (int k, int l, int r, int b, int e, int s) {
if(l == b && e == r) {
f[k] += (r - l + 1) * s;
v[k] += s;
return;
}
pushdown(k, l, r);
int m = (l + r) >> 1;
if (e <= m) {
modify(2 * k, l, m, b, e, s);
} else if (b > m) {
modify(2 * k + 1, m + 1, r, b, e, s);
} else {
modify(2 * k, l, m, b, m, s), modify(2 * k + 1, m + 1, r, m + 1, e, s);
}
pushup(k);
}
ll query(int k, int l, int r, int b, int e) {
if (l == b && e == r) {
return f[k];
}
pushdown(k, l, r);
int m = (l + r) >> 1;
ll res;
if (e <= m) {
res = query(2 * k, l, m, b, e);
} else if (b > m ) {
res = query(2 * k + 1, m + 1, r, b, e);
} else {
res = query(2 * k, l, m, b, m) + query(2 * k + 1, m + 1, r, m + 1, e);
}
pushup(k);
return res;
}
int main () {
int n, m; cin >> n >> m;
for (int i = 1; i <= n; i++) {
cin >> a[i];
}
build(1, 1, n);
while (m --) {
int t; cin >> t;
if (t == 1) {
int b, e, x; cin >> b >> e >> x;
modify(1, 1, n, b, e, x);
} else {
int b, e; cin >> b >> e;
cout << query(1, 1, n, b, e) << endl;
}
}
return 0;
}
线段树实战
旅馆
一家旅馆共有 N 个房间,这 N 个房间是连成一排的,标号为 1∼N。
现在有很多旅客以组为单位前来入住,每组旅客的数量可以用 Di来表示。
旅店的业务分为两种,入住和退房:
- 旅客入住时,第 i 组旅客需要根据他们的人数 Di,给他们安排 Di 个连续的房间,并且房间号要尽可能的小。如果房间不够,则无法安排。
- 旅客退房时,第 i 组旅客的账单将包含两个参数 Xi 和 Di,你需要将房间号 Xi到 Xi+Di−1之间的房间全部清空。
现在你需要帮助该旅馆处理 M 单业务。
旅馆最初是空的。
输入数据
第一行输入两个用空格隔开的整数 N 和 M。
接下来 M 行将描述 M 单业务:
“1 Di”表示这单业务为入住业务。
“2 Xi Di”表示这单业务为退房业务。
输出数据
每个入住业务输出一个整数,表示要安排的房间序列中的第一个房间的号码。
如果没办法安排,则输出 0。
每个输出占一行。
数据范围
1≤Di≤N≤50000 1≤M<50000
输入样例:
2
3
4
5
6
7
1 3
1 3
1 3
1 3
2 5 5
1 6输出样例:
2
3
4
5
4
7
0
5
题意解析
对于长度为N的01串(下标从1开始), 需实现以下两种操作: * 查询串中最靠左的长度为d的全0串, 并返回左端点(若不存在返回0); 随后把这个全0串变成全1串。 * 把区间[x, x + d - 1]变成全0
思路
设计线段树的结点保存区间的三种信息: - 区间中的最长0串长度 - 区间中以左端点开始的最长0串长度 - 区间中以右端点结束的最长0串长度
这样设计的巧妙之处在于: - 由两个子区间的信息可以推出当前区间的信息 - 通过三个信息可以递归查找出最左的长度为d的0串
代码
1 |
|
最长递增子序列
给你一个整数数组 nums 和一个整数 k 。
找到 nums 中满足以下要求的最长子序列:
子序列 严格递增 子序列中相邻元素的差值 不超过 k 。 请你返回满足上述要求的 最长子序列 的长度。
子序列 是从一个数组中删除部分元素后,剩余元素不改变顺序得到的数组。
示例 1:
输入:nums = [4,2,1,4,3,4,5,8,15], k = 3 输出:5 解释: 满足要求的最长子序列是 [1,3,4,5,8] 。 子序列长度为 5 ,所以我们返回 5 。 注意子序列 [1,3,4,5,8,15] 不满足要求,因为 15 - 8 = 7 大于 3 。 示例 2:
输入:nums = [7,4,5,1,8,12,4,7], k = 5 输出:4 解释: 满足要求的最长子序列是 [4,5,8,12] 。 子序列长度为 4 ,所以我们返回 4 。 示例 3:
输入:nums = [1,5], k = 1 输出:1 解释: 满足要求的最长子序列是 [1] 。 子序列长度为 1 ,所以我们返回 1 。
提示:
1 <= nums.length <= 105 1 <= nums[i], k <= 105
来源:力扣(LeetCode) 链接:https://leetcode.cn/problems/longest-increasing-subsequence-ii 著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
思路分析
可以注意到数组的元素值是有范围的, 位于[1, 1e5]。
定义a[j]为在数组nums中[0, i]以j结尾的满足题意的最长递增序列长度; 则当考虑nums[i + 1]是, 只需要把nums[i + 1]加到某个序列的末尾, 此序列的最后一个元素x应该满足:x < nums[i + 1] , x >= nums[i + 1] - k.
可以得到x的范围为[nums[i + 1] - k, nums[i + 1] - 1], 在此区间查找最长的子序列长度, 在更新a[nums[i + 1]]即可。
查询某区间的最大值, 显然可以使用线段树。
代码参考
时间复杂度:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52const int N = 1e5 + 10;
int f[N << 2];
void modify (int u, int l, int r, int x, int v) {
if (l == r) {
f[u] = max(f[u], v);
return;
}
int m = (l + r) >> 1;
if (x <= m) {
modify(2 * u, l, m, x, v);
} else {
modify(2 * u + 1, m + 1, r, x, v);
}
f[u] = max(f[2 * u], f[2 * u + 1]);
}
int query (int u, int l, int r , int b, int e) {
if (l == b && r == e) {
return f[u];
}
int m = (l + r) >> 1;
if (e <= m) {
return query(2 * u, l, m, b, e);
} else if (b > m) {
return query(2 * u + 1, m + 1, r, b, e);
} else {
return max(query(2 * u, l, m, b, m),
query(2 * u + 1, m + 1, r, m + 1, e));
}
}
class Solution {
public:
int lengthOfLIS(vector<int>& nums, int k) {
memset(f, 0, sizeof f);
int mx = 0;
for (auto i : nums) {
mx = max(i, mx);
}
for (auto i : nums) {
int t;
if (i == 1) {//特判1, 因为比1小的数不在线段树区间范围内
t = 0;
} else {
t = query(1, 1, mx, max(1, i - k), i - 1);
}
modify(1, 1, mx, i, t + 1);
}
return f[1];
}
};